ETA Plots
Kyle Baron
2020-06-30
eta.RmdSet up
library(pmplots) library(dplyr) data <- pmplots_data_id()
A good workflow is to create a character vector of your etas and their names.
etas <- c("ETA1//ETA-CL", "ETA2//ETA-VC", "ETA3//ETA-KA") etas
## [1] "ETA1//ETA-CL" "ETA2//ETA-VC" "ETA3//ETA-KA"Note that very frequently, ETA plots come back as a list of plots, one for each ETA.
ETA histogram
## Loading required namespace: cowplot## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.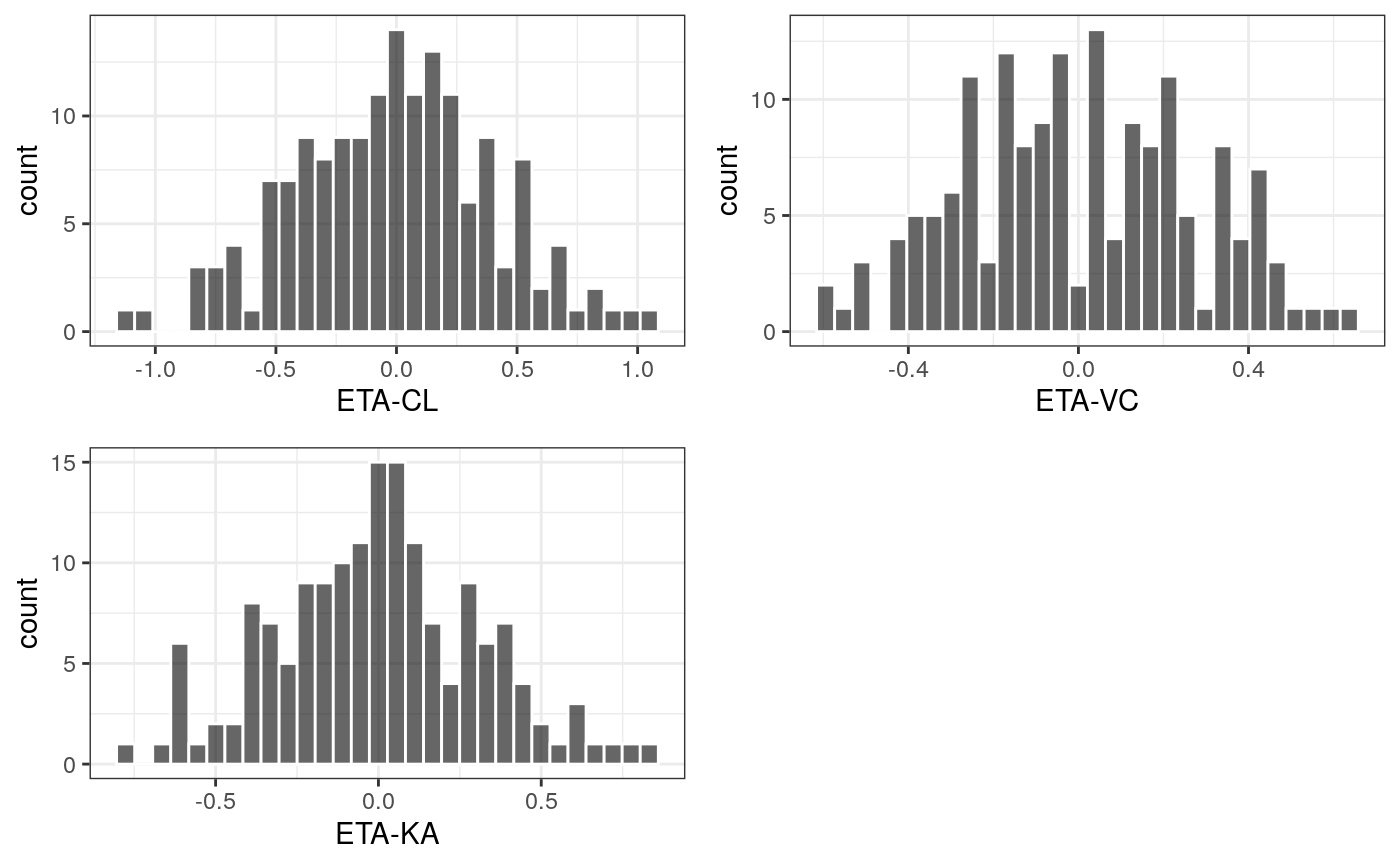
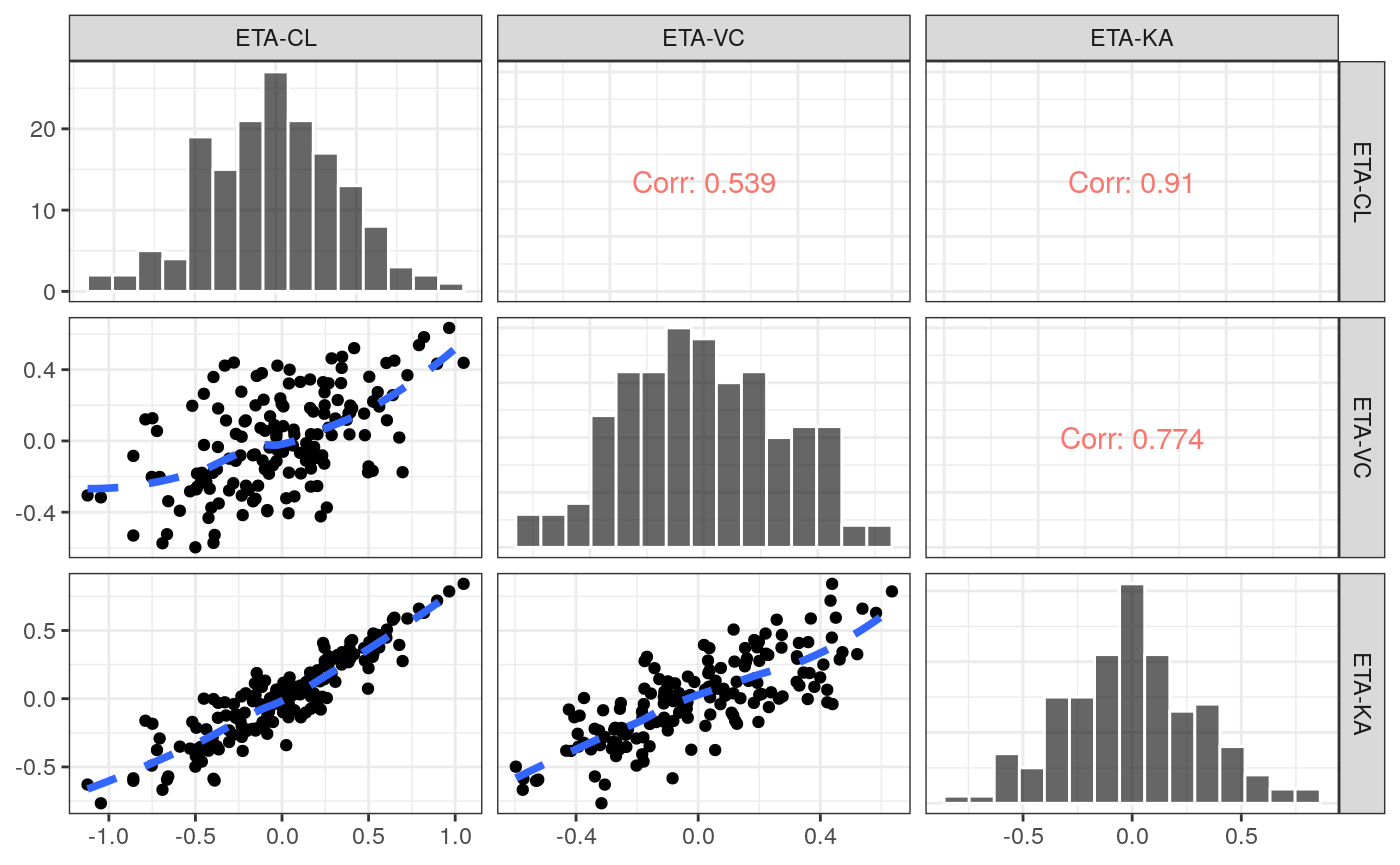
ETA Pairs
eta_pairs(data,etas)
## Loading required namespace: GGally## Registered S3 method overwritten by 'GGally':
## method from
## +.gg ggplot2## `geom_smooth()` using formula 'y ~ x'
## `geom_smooth()` using formula 'y ~ x'
## `geom_smooth()` using formula 'y ~ x'